by Paul Whittaker
•
3 June 2025
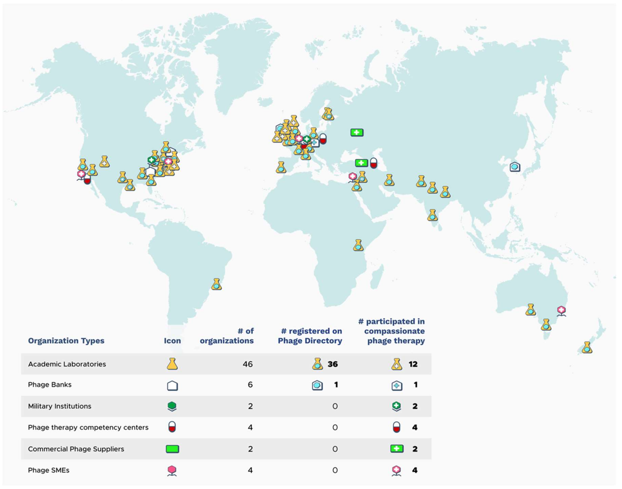
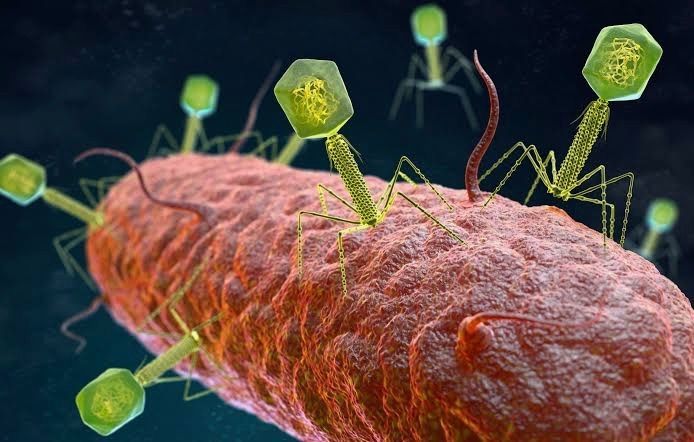
Image Source: The growing global problem of antibiotic resistance , and the lack of new antibiotics being developed, has rekindled an interest in phage therapy: the use of viruses (bacteriophages) that specifically target and kill bacteria, as a treatment for antibiotic resistant infections in humans. This article is an overview of phage therapy and is the first in a series where I will explore aspects of this technology in greater detail. Links to papers and websites that contain diagrams or graphics relevant to this article are provided at the end of this article, as are links to PubMed search results for phage therapy papers, reviews and clinical trials. Bacteriophages In 1986, nanotechnology pioneer K. Eric Drexler imagined a dystopia where invisible self-replicating nanobots proliferated voraciously and took over the entire planet. Spooked by Drexler’s nightmare, Prince Charles (the heir to the British throne at the time, but now King Charles III) requested that the eminent Royal Society investigate the risks that nanotechnology posed. However, the reality is that nano-scale self-replicating voracious killers have existed on earth for over 4 billion years. They can make hundreds of copies of themselves in as little as 15 minutes, and are found in vast numbers everywhere on our planet. Thankfully, they are not harmful to humans. Instead, they infect and destroy bacteria in a process perfected over the eons. Known as bacteriophages , these biological entities were discovered at the beginning of the twentieth century. Bacteriophages (usually referred to as phages - derived from the Greek word “phagein”, meaning “to devour/eat”) are viruses composed of a nucleic acid genome encased in a phage-encoded protein capsid shell. Phages are found in three basic structural forms : icosahedral head with a tail; icosahedral head without a tail; and filamentous. They infect and kill bacteria by replicating inside bacterial cells, then breaking open ( lysing ) the infected cells before releasing large numbers of new progeny phage particles. In the laboratory, this process is visualised and monitored using plaque assays . Phages are ubiquitous and diverse . It has been estimated that there are 10 31 bacteriophages on the planet, more than every other organism on Earth, including bacteria. Phages can be isolated from sources where high numbers of bacteria occur, such as human sewage , soil , rivers , faeces , even slime in a stream . Phages are specific to individual bacterial species and strains and do not infect mammalian cells. However, because of the microbiome , the human body contains large numbers of phage particles and varieties of phages (the so called phageome ) and, as a result, phage can interact with mammalian cells. Phages are fascinating biological entities. As an undergraduate biology student I learned of the importance of phages as key experimental tools in the development of the fields of molecular genetics and molecular biology. As a post-graduate biochemistry student I worked with phages in the lab of the late Pauline Meadow , who used them as a way of identifying lipopolysaccharide (LPS)-defective mutants of Pseudomonas aeruginosa. As a doctoral student in molecular biology working on DNA methylation in the slime mould Physarum polycephalum, and as a postdoctoral researcher working on human genome analysis, I used phage lambda cloning vectors to construct genomic DNA libraries for gene isolation (e.g. tubulin genes from the parasite Trypanosoma brucei) and for the physical mapping of human genomic DNA (e.g. the human dystrophin-encoding gene using a specially modified phage lambda vector I developed). The Challenge of Bacterial Anti-Microbial Resistance More widely referred to as anti-microbial resistance , or AMR , bacterial AMR (bAMR) occurs when bacteria develop the ability to defeat the antibiotics designed to kill them. This resistance can result from several different mechanisms . I n this article I am referring specifically to bAMR, and not viral, fungal, or parasitic AMR . A systematic analysis published in 2022 estimated that there were 4.95 million deaths associated with bAMR globally in 2019. As a result, bAMR has the potential to affect each and every one of us by impacting the treatment of illnesses, surgical procedures and cancer treatment, as well as increasing rates of death. The increase in prevalence of bAMR has led to fears of future pandemics caused by drug-resistant bacteria. In the UK, the Government and the National Health Service (NHS) have both developed action plans to tackle bAMR which emphasise optimising and reducing exposure to antibiotics. Despite these measures, however, new antibiotics and alternatives to antibiotics are still needed, particularly in cases where infections are refractory to antibiotic use. Developing new classes of antibiotics is challenging . The greater portion of recently approved antibiotics have tended to be derivatives of existing classes of drug compounds. Although pharmaceutical giant Roche recently reported the identification of a promising new class of antibiotic molecules that target carbapenem-resistant Acinetobacter baumannii (CRAB), many big pharma companies have ceased antibiotic development. As a result, small biotech companies are leading research and development efforts in this area. Phage Therapy Case studies in the scientific literature , and success stories described in the press and in books have highlighted the use of phage therapy to treat infections caused by antibiotic-resistant bacterial strains. However, phage therapy as a way of treating bacterial infections is not new. Phages were first used to treat bacterial infections in 1919 (the “pre-antibiotic era”), but the approach never really gained traction in the West, particularly after penicillin was discovered in 1928 and became the favoured way to treat bacterial infections in the 1940s. Despite this, phages have continued to be used in Russia , Georgia and Poland as an alternative to antibiotics since the early 20 th century . The excellent book “The Good Virus” by Tom Ireland, gives a vivid and detailed account of the history of phage therapy and how interest in it as an approach to treating bacterial infections has waxed and waned over the past century. Now, because of the growing threat of bAMR, there has been a resurgence of interest in using phages to tackle antibiotic resistant infections. As some phages degrade biofilms, phage therapy also potentially provides a way to deal with the antibiotic tolerance seen in some chronic diseases resulting from biofilm production (e.g. cystic fibrosis ). Also of interest is the potential to use phage resistance as a way to steer bacteria towards an antibiotic-sensitive phenotype. Unfortunately, in many parts of the world current regulations restrict the application of phage therapy to individual 'compassionate use ' in patients with infections where antibiotics have failed. In the UK phage therapy has been used sparingly to treat Pseudomonas and Mycobacterial infections mainly due to the lack of sustainable access to phages manufactured to good manufacturing practice ( GMP ) standard. The first successful clinical trial of phage therapy in the UK was published in 2009. Since then, phage therapy has been used in the treatment of patients with diabetic foot ulcers and cystic fibrosis . There has often been a difference between the results of individual real world case reports of successful phage therapy and the results of larger scale studies. Therefore, high quality clinical trials of phage therapy in the treatment of a range of conditions are needed to provide a solid evidence base on the efficacy and safety of phage therapy in human patients to support wider clinical use. A retrospective observational analysis of 100 consecutive cases of personalised phage therapy carried out by a Belgian consortium using combinations of 26 bacteriophages and 6 defined bacteriophage cocktails reported clinical improvement and eradication of targeted bacteria for 77.2% and 61.3% of infections, respectively. However, eradication was 70% less when antibiotics were not used concurrently. Recently, there have been calls for the British Government to invest in phage therapy as a way to tackle bAMR. As a first step, a report published in January 2024, following a Parliamentary Inquiry in 2023, recommended that the British Government bring together phage experts and stakeholders (scientific, clinical and regulatory) to assess what would be required to enable phage therapy to be used more widely in the National Health Service (NHS) and other UK healthcare settings. A Government response to this report which supports these recommendations and makes 18 additional recommendations across 4 themes, has now been published . The Innovate UK Phage Knowledge Transfer Network has been established to provide a forum for funders and phage researchers to discuss these matters and ways forward, including multi-party collaborations and co-investments by public and/or private funders. Discussion The dramatic results seen in sick people who have received phage therapy as a last ditch treatment when conventional antibiotic therapy has failed, provides a compelling narrative for its potential in the treatment of bAMR. However, the body of evidence required to convince regulatory authorities, governments and the medical establishment of phage therapy efficacy is clearly lacking at the moment. Even if that data is forthcoming, it is unlikely that phage therapy will ever replace antibiotics. More likely, phage therapy will continue to be used in a personalised way to treat infections that are resistant to standard antibiotic therapy, but in the future it is reasonable to envisage clinical scenarios where phages might be used in conjunction with antibiotics. The judicious use of phages might help protect and preserve existing antibiotics and combining the two appears to be more effective than either on their own. Phage therapy may also be useful for treating people who are allergic to antibiotics and may not have other treatment options. It is, of course, entirely possible that phage therapy for humans never progresses past the stage it is at now. Maybe new classes of antibiotics will be discovered. Maybe other antimicrobial therapeutic modalities will be invented, or discovered. Hopefully, though, the many initiatives taking place worldwide will result in the development of a safe and clinically proven version of phage therapy that will become part of an expanded therapeutic toolkit. However, what is clear at present is that while these challenges are being tackled, phages are already being deployed in various animal and non-medical scenarios such as food safety and environmental pathogen control (e.g. aquaculture ). As I explored the extensive literature around phage therapy , I realized that I could only scrape the surface of this subject in such a short article. But it is a fascinating field with therapeutic potential. Therefore, in later blog articles, I will discuss aspects of phage therapy; such as safety, phage production, commercialisation, and the regulatory approaches to using phage therapy in different countries round the world, including the UK, in more detail. Links to websites and papers with relevant diagrams and graphics: Structure of a bacteriophage Bacteriophage life cycle Phage lambda structure How bacteriophages infect and lyse bacterial cells Phage therapy Bacteriophage plaque assay Overview of antimicrobials Antibiotic Resistance Causes of antibiotic resistance Antimicrobial resistance worldwide PubMed literature links: Bacteriophage papers Bacteriophage therapy papers Bacteriophage therapy reviews Bacteriophage therapy randomised controlled trials Phage therapy systematic reviews